软件名称:网页自动化助手 - 域名爬虫
官网:https://www.192219.com
作者:网页自动化助手
1)域名爬虫工具:多线程采集、去重过滤、一键保存
2)批量采集域名/网址:支持深度爬取 + 过滤三级域名
3)关键词/域名采集助手:快速整理站点列表(Win桌面版)
4)网站域名采集器:从起始网址自动提取域名,效率拉满
5)站点线索收集工具:排除域名、标题匹配、结果自动保存
6)网页自动化助手:域名爬虫/采集工具(支持多线程)
一、软件简介
====================
本软件是一款桌面端域名/网址采集工具,面向“批量收集、整理、筛选域名/网址数据”的需求场景。
可通过两种方式获取数据:
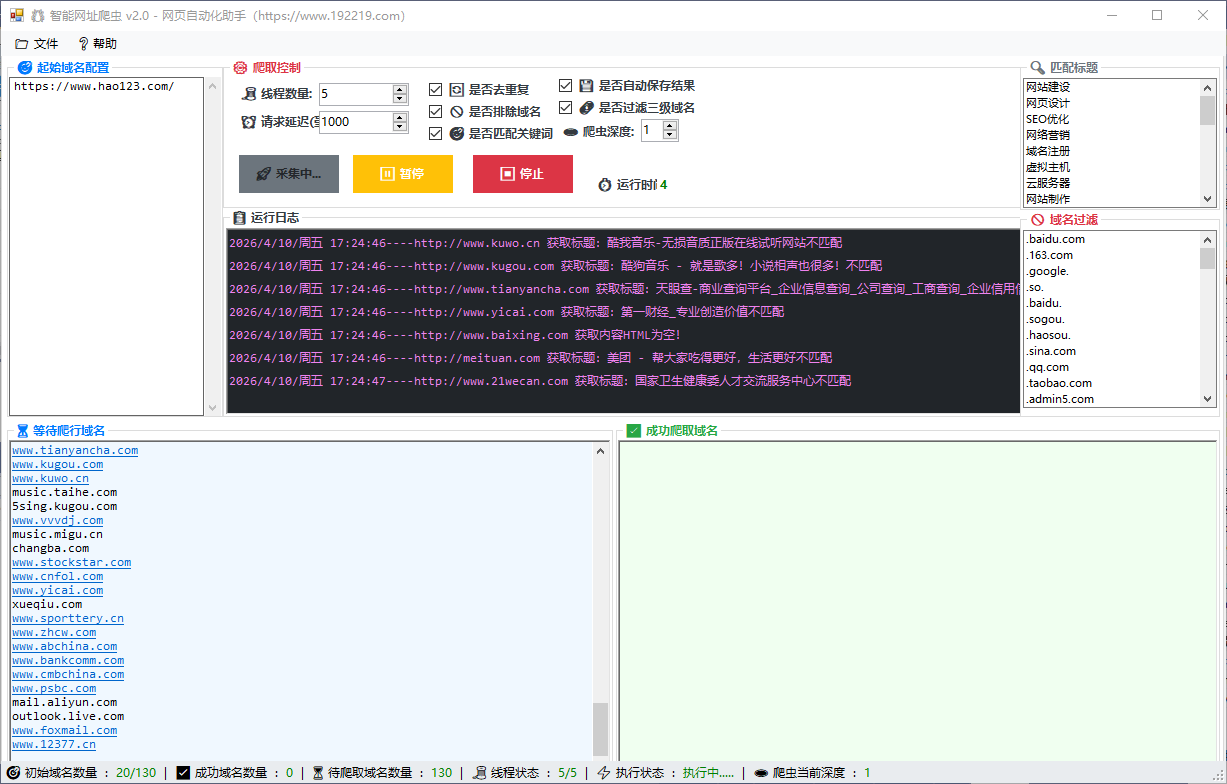
1)网址爬虫:从一个或多个起始网址出发,自动解析页面链接并提取域名,支持多层深度爬取。
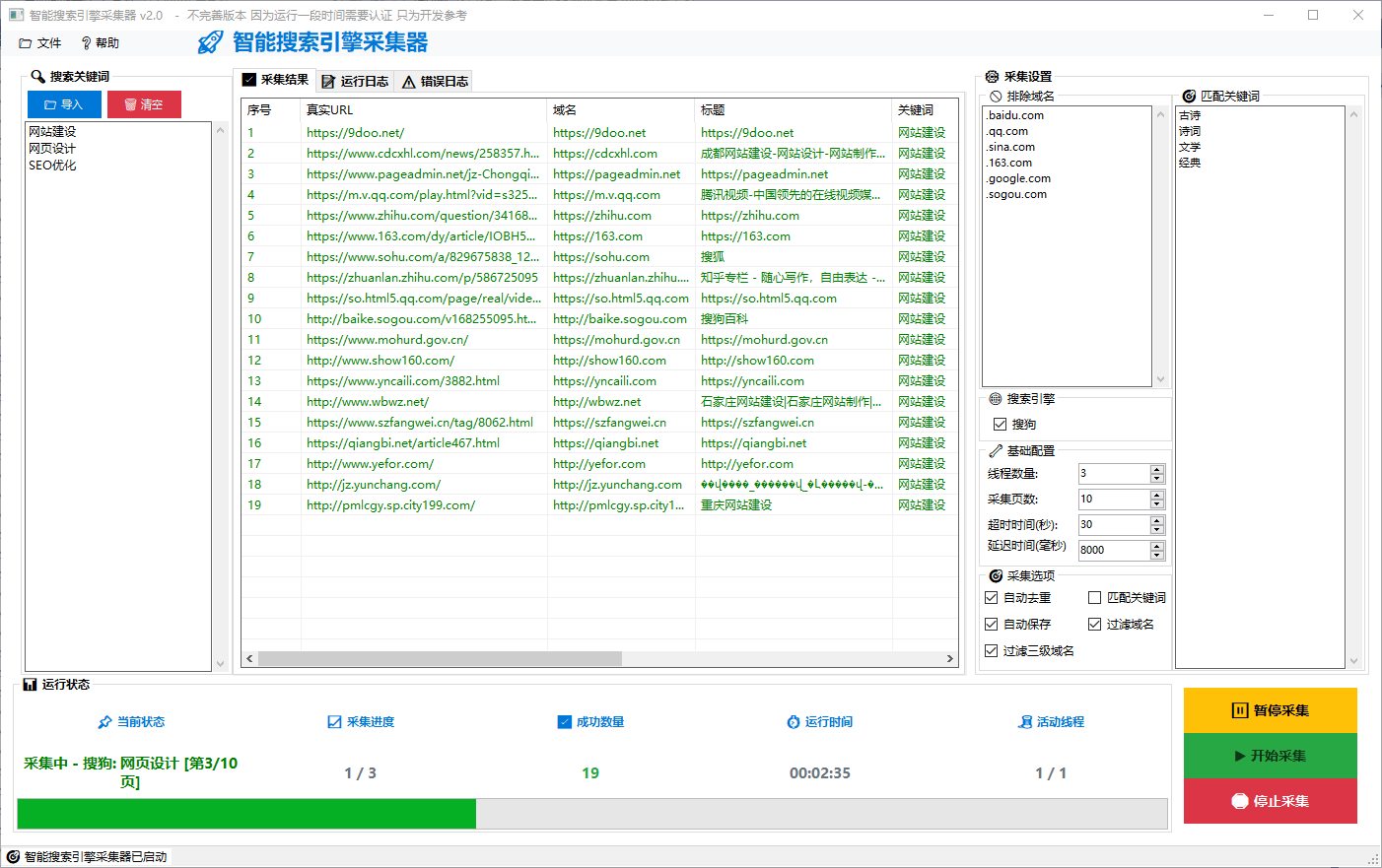
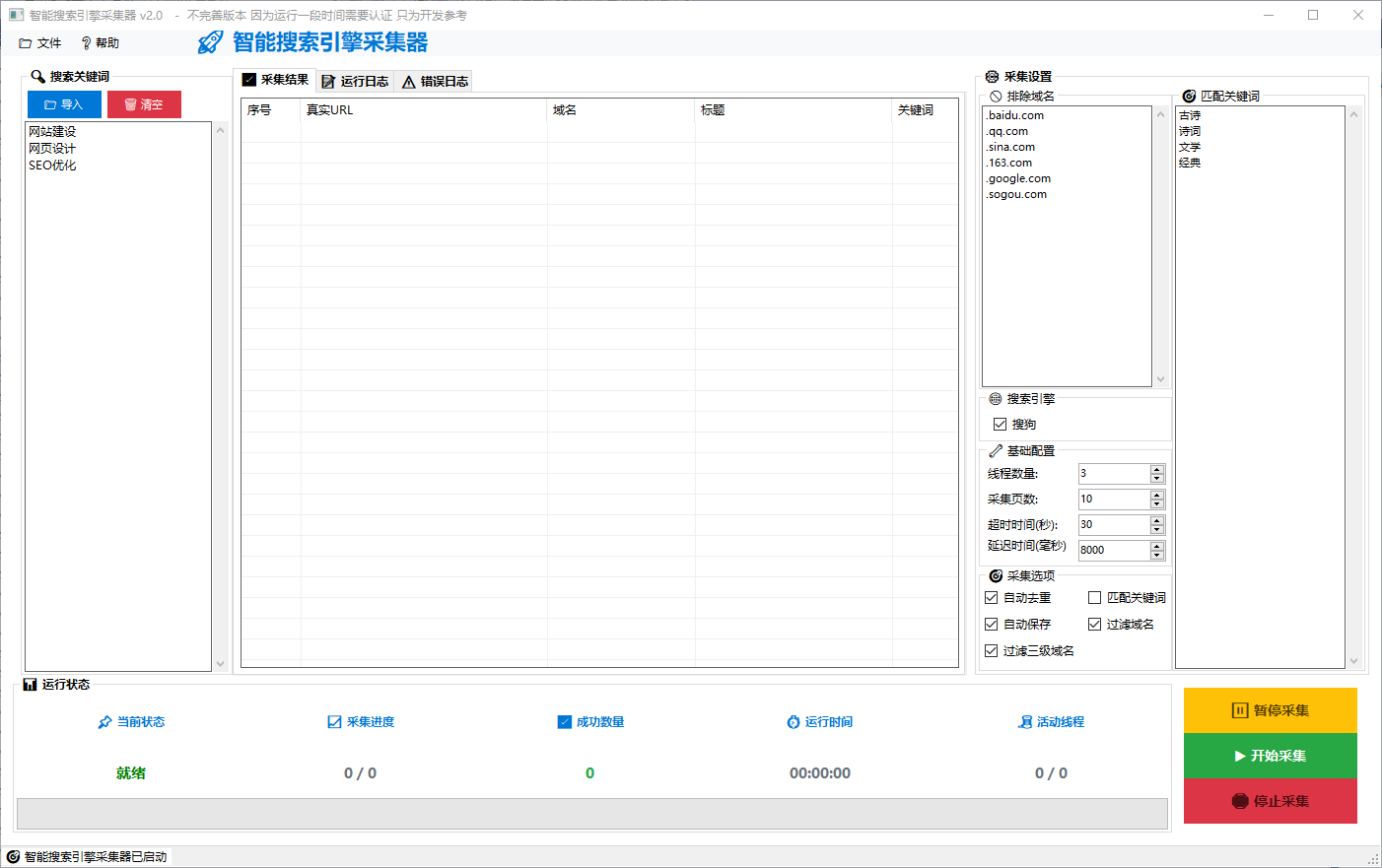
2)搜索引擎采集器:基于关键词从搜索引擎获取结果并解析域名/标题等信息(视当前版本实现情况而定)。
====================
二、核心功能
====================
【采集能力】
- 多线程并发采集,提高效率
- 自定义爬虫深度(层级扩展)
- 自定义超时、延迟,降低被限制风险
【数据处理】
- 自动去重(大小写不敏感)
- 过滤三级及以上域名(可选)
- 排除指定域名/域名片段(可选)
- 标题关键词匹配筛选(可选)
【结果与日志】
- 采集过程实时日志输出
- 采集结果可保存到 result 目录(按时间戳命名)
====================
三、适用场景
====================
- 站点线索收集与整理
- 行业站点/竞品域名初筛
- 数据分析前的数据准备(去重/过滤/汇总)
====================
四、合规与免责声明(建议)
====================
- 请遵守目标站点服务条款与 robots 规则,合理控制频率。
- 采集结果请用于合法合规用途,严禁用于侵权、违法或恶意行为。
软件名称:网页自动化助手 - 域名爬虫
官网:https://www.192219.com
作者:网页自动化助手
====================
一、运行前准备
====================
1. 确保网络可用(建议稳定网络)。
2. 建议首次使用先用少量网址、较小深度测试。
3. 如遇到目标网站限制/验证码/频率限制,适当加大“请求延迟”,降低“线程数量”与“深度”。
====================
二、功能入口说明
====================
当前项目包含两类窗口(以实际版本界面为准):
【网址爬虫】
- 从起始网址出发,解析页面链接,提取并扩展域名(支持深度)。
【搜索引擎采集器】
- 输入关键词后从搜索引擎获取结果并提取域名/标题等信息(部分功能可能在开发/参考阶段)。
====================
三、网址爬虫:推荐使用流程
====================
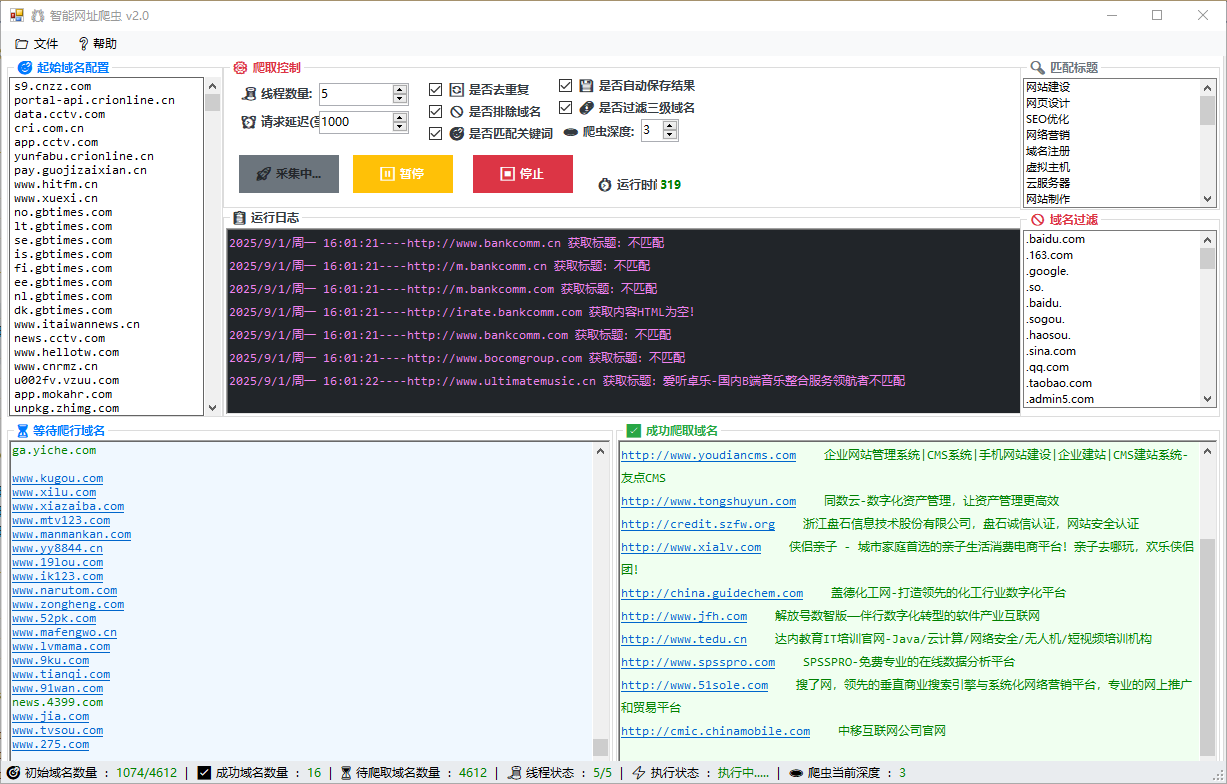
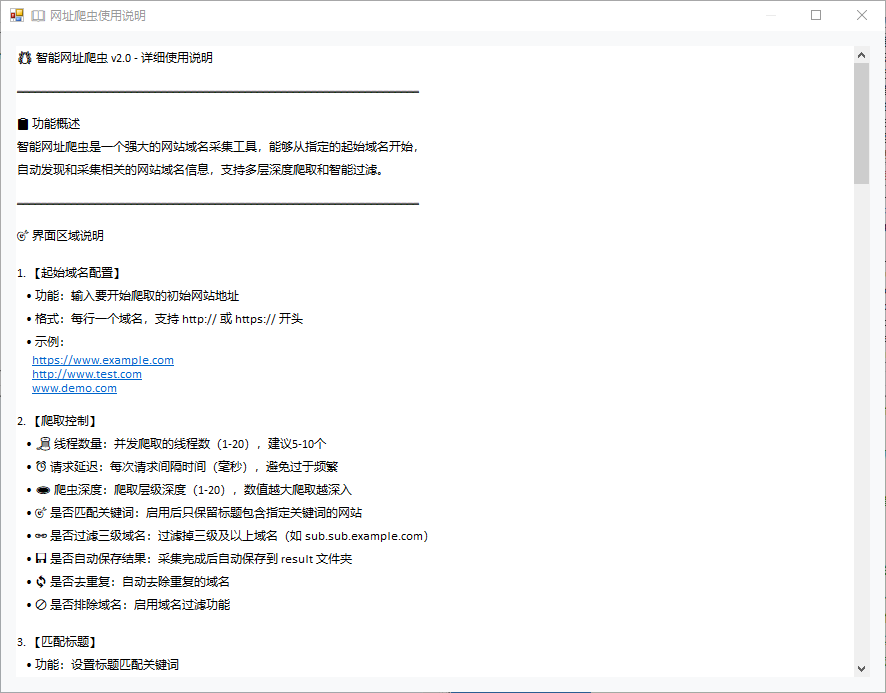
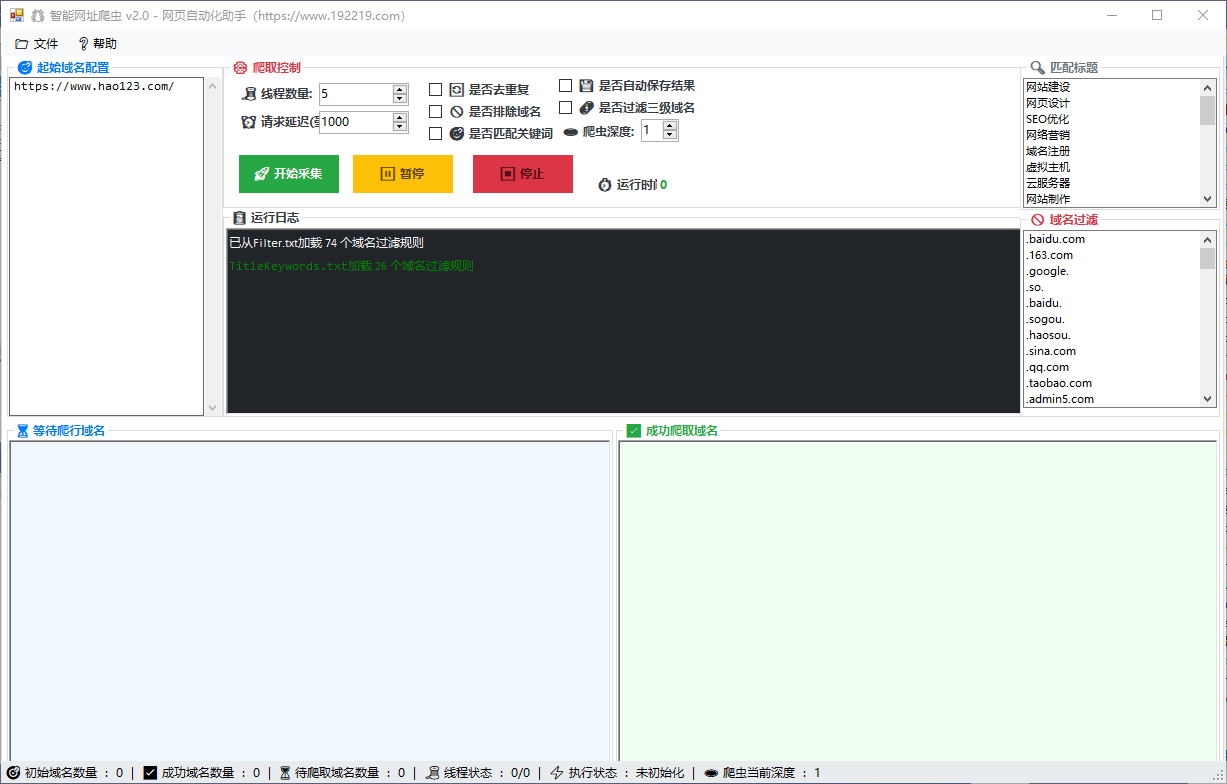
步骤1:填写起始网址
- 在“起始域名配置/初始域名集合”中输入网址
- 支持多行输入:一行一个
- 支持格式:
- https://www.example.com
- http://www.example.com
- www.example.com(程序会自动补全协议)
步骤2:设置参数
- 线程数量:建议 3-10(越大越快,但更容易触发限制)
- 请求超时:建议 3000-10000 毫秒(看网络情况)
- 请求延迟:建议 1000-5000 毫秒(降低被限制概率)
- 爬虫深度:
- 1:仅处理起始网址
- 2:处理起始网址 + 起始页中的链接域名
- 3+:继续扩展(越大越慢、数据越多)
步骤3:按需勾选过滤项
- 是否去重复:建议开启
- 是否过滤三级域名:需要更“主域名”数据时可开启
- 是否排除域名:开启后会按“域名过滤”列表排除匹配项
- 是否匹配关键词:开启后仅保留标题包含“匹配标题”列表关键词的结果
- 是否自动保存结果:开启后采集完成会自动写入 result 目录
步骤4:开始采集
- 点击“开始采集”
- 运行中可点击“停止”
- 观察“日志/状态栏”了解进度与是否存在错误
步骤5:查看与导出
- 结果会展示在成功列表/文本框中
- 如开启自动保存:结果保存路径为程序目录下的 result 文件夹,文件名为时间戳(如 20260410123045.txt)
====================
四、常见问题(排查建议)
====================
1)采集速度慢
- 降低深度、减少起始网址数量
- 合理增大线程数(不要过大)
- 检查是否被目标站点限制(大量失败/空内容)
2)采集失败/HTML为空
- 目标站点可能启用了反爬/需要登录/需要验证码
- 增加请求延迟、降低线程
- 更换起始网址或降低深度
3)结果太多、噪音大
- 开启“过滤三级域名”
- 配置“排除域名”
- 开启“匹配关键词”并补充匹配词
====================
五、联系与更新
====================
如需更多功能/定制需求,请访问官网:
https://www.192219.com